Comparing OpenAPI / Swagger, GraphQL, and gRPC
I’ve been preparing for a talk at Twin Cities Code Camp 2020 which will compare and contrast the more common and traditional OpenAPI or Swagger APIs (sometimes called REST APIs in a generally-accepted loose interpretation of the term) and the newer kids on the block: GraphQL and gRPC.
Most of us are probably familiar with the existing OpenAPI, or Swagger, flavor of APIs and documents. When you develop such an API using ASP.NET Core, you use Controllers to define your routes and you can use a library like Swashbuckle to enable some interactive testing and experimenting with the API, as well as enabling consumers to look at and explore the routes and response types. The user interface looks like this:
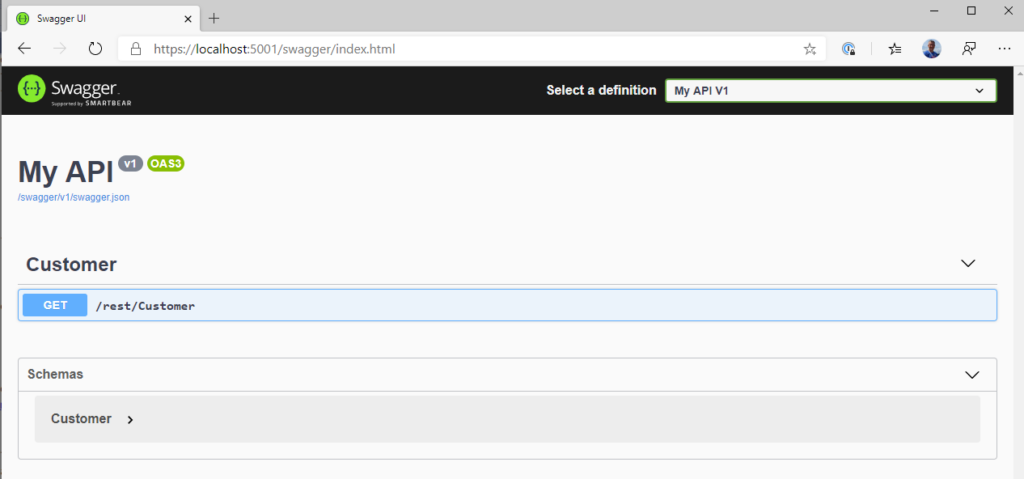
What’s wrong with OpenAPI/Swagger?
Nothing, really. This protocol will continue to evolve and develop, and has a completely legitimate place in modern applications.
So why were GraphQL and gRPC created?
TL;DR: GraphQL is really all about letting the consumer get only what they really want and also explicitly separating queries, updates (mutations in GraphQL lingo) and getting notified when updates happen (subscriptions). gRPC is all about efficiency on the wire by using a very efficient binary transport and built-in security.
This question (why do we have these new protocols) is really the crux of the whole discussion. The context around the answer kind of depends on how you interpret OpenAPI/Swagger (I’ll just say OpenAPI going forward).
The OpenAPI spec defines routes, and the routes can have QueryString parameters and/or well-defined content that gets included in Request bodies, as well as well-defined content that gets returned in the Response body. This Response body can sometimes vary in format through content negotation but is most often JSON content.
Consider the following snippet from the response of the API pictured above.
1{
2 "customerId": "ALFKI",
3 "companyName": "Alfreds Futterkiste",
4 "contactName": "Maria Anders",
5 "contactTitle": "Sales Representative",
6 "address": "Obere Str. 57",
7 "city": "Berlin",
8 "region": null,
9 "postalCode": "12209",
10 "country": "Germany",
11 "phone": "030-0074321",
12 "fax": "030-0076545"
13 }
This is a well defined object in the response of the OpenAPI route. If I only want the first three fields, tough — I have no choice but to get the whole object. Also, the object itself is a little self-describing: with an array of these objects I’m going to be getting the text “customerId” repeated with every item in the array (along with ever other field name). This makes for easy comprehension of what’s being transmitted, but also adds some overhead.
Introducing GraphQL
GraphQL was built to address some of the shortcomings of the OpenAPI-based approach. It lets consumers ask for (and get) only what they need. It also provides the ability to alias field names, as well as providing explicit capabilities to separate reads from updates — it refers to updates as mutations — and getting notifications when updates have occurred (subscriptions).
Ignoring the mutations and subscriptions concepts for now, in the above example Customer response, I can write a query that enables me to only get the first three fields if those are what I want. A query like this (which is easily developed using a "playground" user interface or something like GraphiQL):
1{
2 customers {
3 customerId,
4 companyName,
5 contactName
6 }
7}
The abvove will yield a response that looks like this:
1{
2 "customerId": "ALFKI",
3 "companyName": "Alfreds Futterkiste",
4 "contactName": "Maria Anders"
5}
And if I wanted to alias the columns to trim the response or map to my own objects a little better:
1{
2 customers {
3 id: customerId,
4 compNm: companyName,
5 ctctNm: contactName
6 }
7}
The above query provides desired-alias names for all three of the fields and each customer in the response would look like this:
1{
2 "id": "ALFKI",
3 "compNm": "Alfreds Futterkiste",
4 "ctctNm": "Maria Anders"
5}
The functionality to ask for only the fields you want as well as being able to provide alias names for them is pretty compelling in and of itself. Add to that the built-in support for mutations and subscriptions, as well as versioning (which can often be overlooked in OpenAPI implementations) and GraphQL has some good reasons to give it a solid look.
Introducing gRPC
gRPC, on the other hand, was built to address some other shortcomings of OpenAPI methods. Namely, the inefficiency of JSON as wire transport when it comes to chatty things like microservices or IoT devices which may involve very chatty API calls in a very consistent format – and go across a wide variety of application technologies (from .NET to Java to Ruby and more).
gRPC is built around Protobuf files which allow for the definition of explicit contracts around input and output message types and the service methods that will use those message types. It also has some built-in provisioning around the security around gRPC calls as well as versioning support.
A key drawback or limitation of gRPC (at present) is that it is not really meant to support front-end web clients (think JavaScript / TypeScript / etc), and it requires HTTP/2 and TLS or SSL on the wire. This means that it cannot run in IIS or in Azure App Services and it is not really meant to sit directly behind a web-based SPA. Most common use cases are within microservices (service to service communication), small-footprint IoT devices running native/compiled code, or even internal service communication (maybe even behind a gateway used in a back-end-for-front-end / BFF style).
To define the entire service as shown above in a Protobuf file you would have a file that looks like this:
1syntax = "proto3";
2option csharp_namespace = "NortwindApiSampler.Services";
3import "google/protobuf/empty.proto";
4
5service CustomerService {
6 rpc GetAllCustomers (google.protobuf.Empty) returns (CustomerResponse);
7}
8message CustomerResponse {
9 repeated CustomerMessage customers = 1;
10}
11message CustomerMessage {
12 string customerId = 1;
13 string companyName = 2;
14 string contactName = 3;
15}
The above file defines a service called CustomerService with no inputs and which would return essentially an array of customers (that’s the repeated keyword).
This Protobuf file makes for very efficient data on the wire (no field names are included, it’s simply order-based), as well as providing a way to build tooling to consume the service for most languages.
Sample API for experimentation
In order to compare and experiment with these protocols, I wanted to create an ASP.NET Core 3.1 API project that included all three, and that’s what I’ve done in this repo: https://github.com/dahlsailrunner/northwind-core-api
This API project sits on top of the sample Northwind database: a Postgres version of it. It exposes a Swagger UI and document for the OpenAPI side of things, a GraphQL Playground to explore GraphQL, and a gRPC endpoint and its protobuf file. Quick shout-out to Andrew Lock who did a blog post that described a pretty clean technique for using common "snake case" column names in Postgres (which the sample Northwind database has) while still using Pascal-case class and property names in C#: https://andrewlock.net/using-snake-case-column-names-with-dapper-and-postgresql/
The readme in the repo describes how to set up the Postgres database (it’s very easy if you have Docker Desktop already installed) and simply running the website will display a "home page" with some information and links as shown below. The nav links across the top are quick ways to access some of the interactive endpoints.
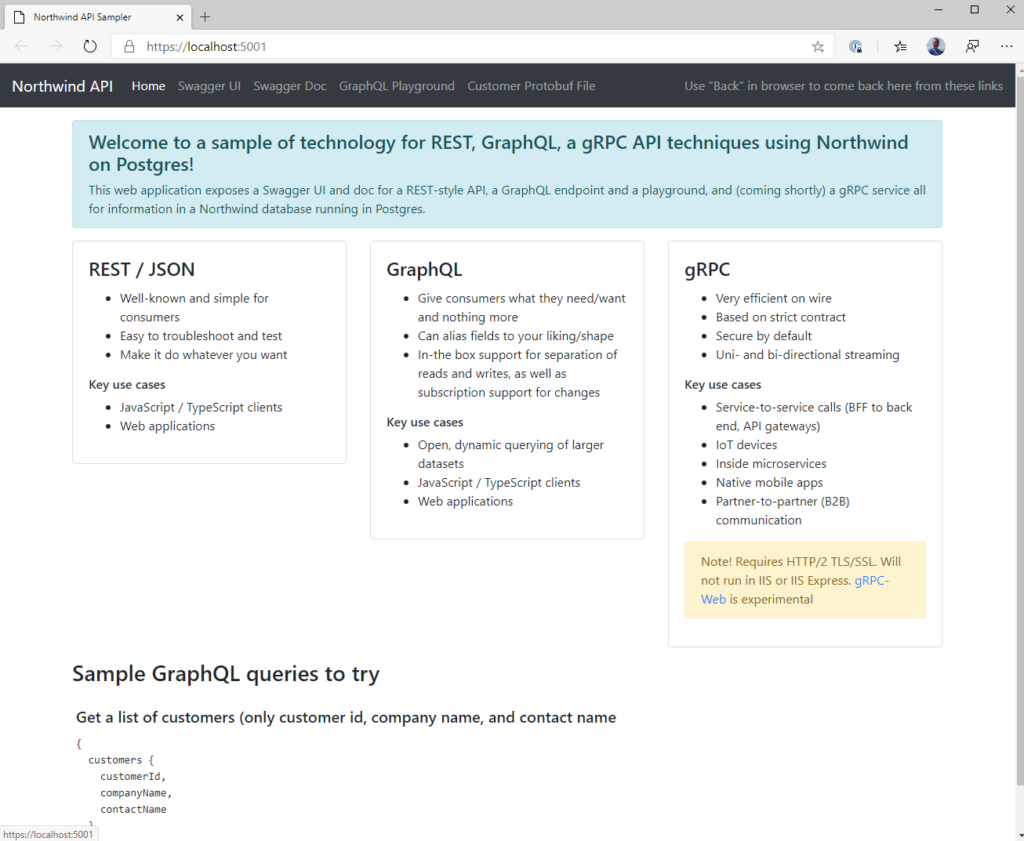
Additionally, there are two additional projects in the repo – console applications for a GraphQL client that simply calls the endpoint and the same thing for a gRPC endpoint.
The Kestrel logging that has been enabled via Serilog shows information about the response data size in case you’re curious. This project is definitely a work-in-progress and may expand to include other things:
- Authentication and Authorization with OAuth2
- Deeper implementation with more routes and objects
- Mutation and subscription support in GraphQL – with websockets
- Streaming support for gRPC
In the meantime, try out the code if you’re interested and I hope some of this has been helpful!